Seit einigen Monaten funktioniert der Personal Hotspot mit Telekom nicht mehr im Ausland.
Siehe z.B. https://telekomhilft.telekom.de/t5/Mobilfunk/Roaming-und-mobiler-Hotspot-funktionieren-nicht-zusammen/m-p/6562491#M680782 oder https://telekomhilft.telekom.de/t5/Mobilfunk/Roaming-Hotspot-funktioniert-nicht/m-p/6659906#M686980 oder https://telekomhilft.telekom.de/t5/Mobilfunk/Persoenlicher-Hotspot-iPhone-IPad/m-p/6730598#M691956.
Ich konnte die Ursache letztlich nicht bis ins Letzte ermitteln.
Aber es hat etwas mit der “Liebe der Telekom und Apple zu iPv6” zu tun 🤭
Update: Es geht auch viel einfacher 🤗
Statt mühsam die Einstellungen in den Mobilgeräten und Macbooks, die den Personal Hotspot nutzen, anzupassen, wird iPv6 ganz einfach im Mobilgerät selbst, das den Hotspot zur Verfügung stellt, deaktiviert.
Dazu die Einstellungen für den APN öffnen mit “Einstellungen” > “Mobilfunk” > “Mobiles Datennetzwerk”.
Infos dazu auch bei Apple: Access Point Name (APN) auf deinem iPhone und iPad anzeigen und bearbeiten. Darin auch der Hinweis: “Wenn du deine APN-Einstellungen vor der Aktualisierung von iOS änderst, werden diese Einstellungen auf die Standardwerte zurückgesetzt. Du musst deine Einstellungen dann nach einer iOS-Aktualisierung möglicherweise erneut eingeben.”
Als APN steht bei Telekom und Congstar standardmäßig internet.v6.telekom – das bringt im Ausland Probleme:
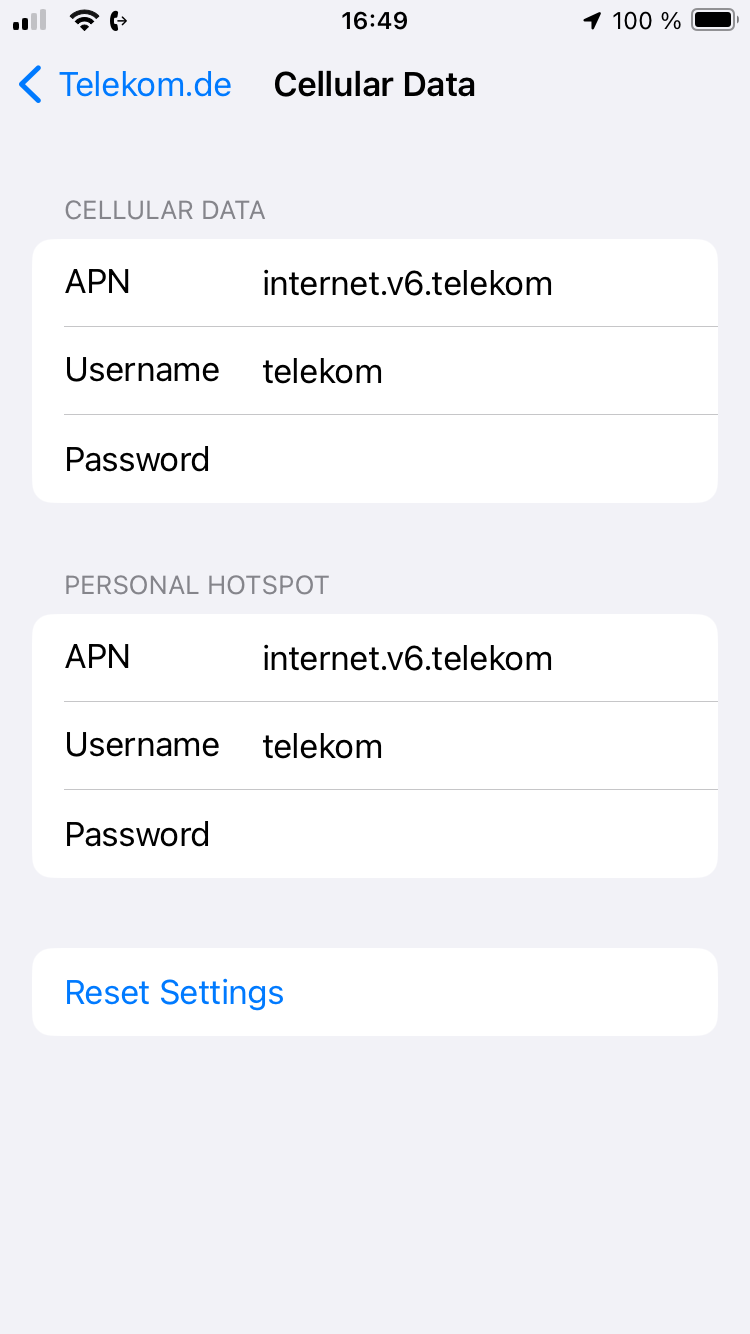
Diese ist zu ändern in internet.telekom (das .v6 weg):
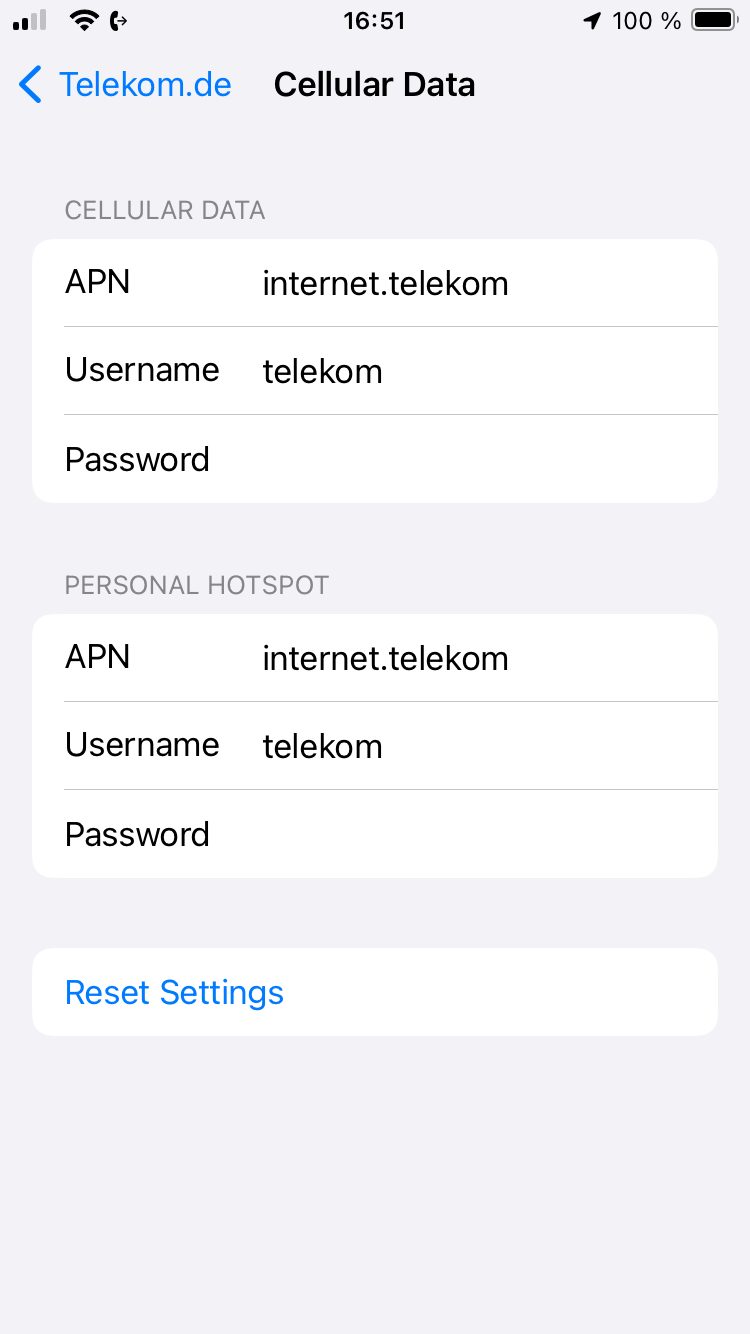
Und zuletzt ganz wichtig: Das iPhone danach herunterfahren / ganz ausschalten und wieder neu starten.
Einfach die mobilen Daten aus- und dann wieder einzuschalten hatte bei mir (und anderen) keine Wirkung. Deshalb dachte ich zuerst, dass die Änderung des APN einfach nicht funktioniert.
Überholte / veraltete Anleitungen: Funktionieren auch, aber unnötig kompliziert ☹️
Hier werden Einstellungen beschrieben, die es Macbooks und iPhones ermöglichen, auch im Ausland den Personal Hotspot des iPhones oder iPads zu nutzen: iPv6 in den Clients des Personal Hotspots deaktivieren.
Am Macbook ist die Abhilfe einfach: iPv6 für das Internet deaktivieren.
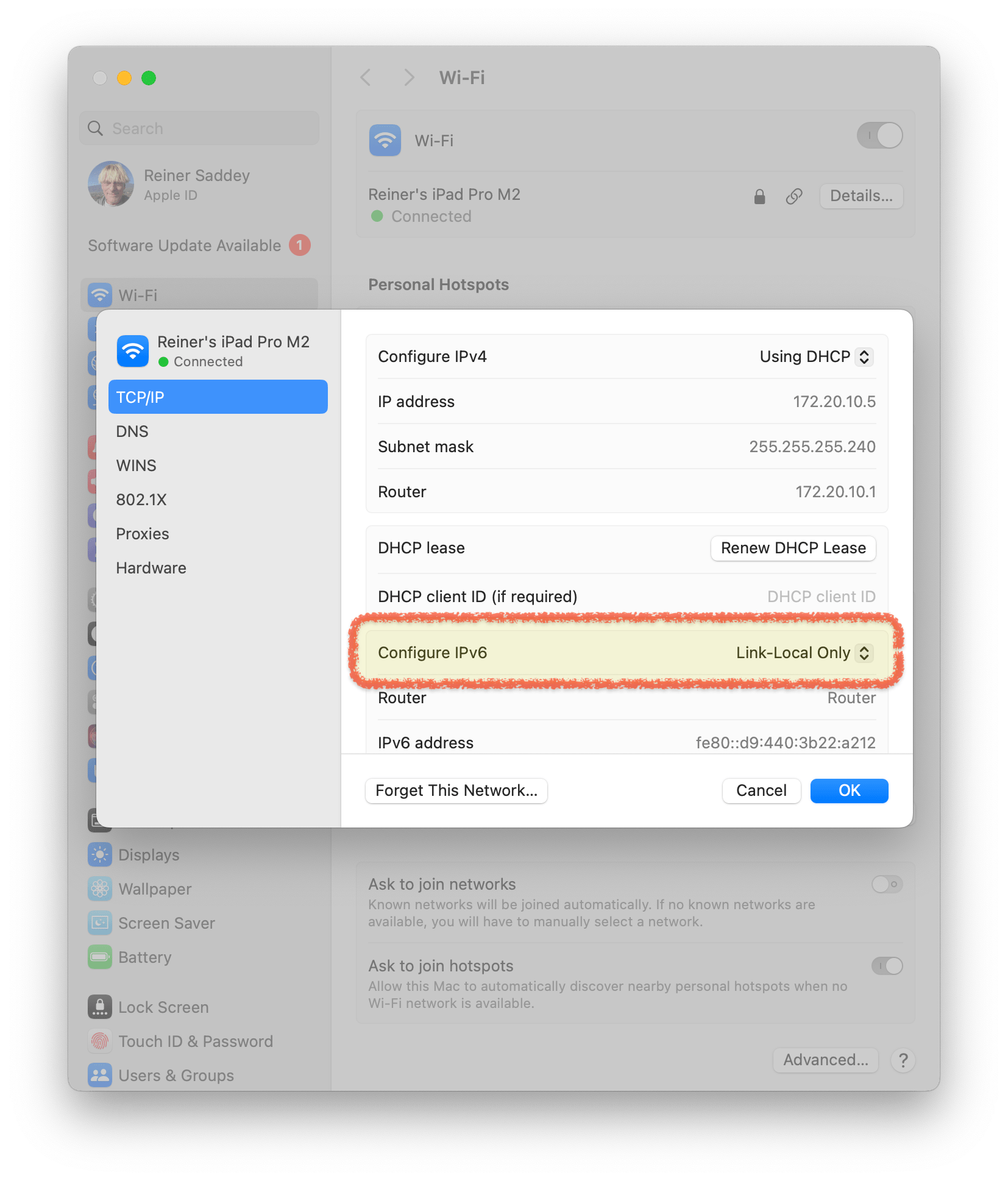
- Bei Rückkehr nach Deutschland wieder “Automatisch” auswählen.
Und bei Nutzung des USB Kabels (statt WLAN)
Im Terminal:
sudo networksetup -setv6off "iPhone USB"Ich selber nutze mein iPad als Hotspot. Deshalb bei mir “iPad USB” statt “iPhone USB”:
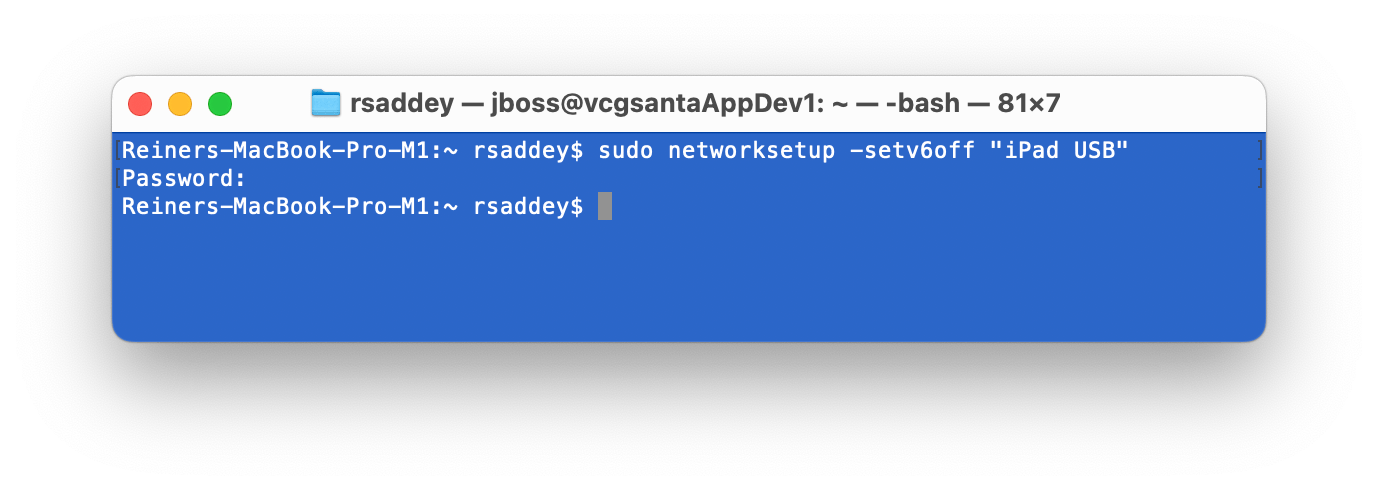
Um, z.B. wieder in Deutschland, iPv6 am USB Kabel wieder zu aktivieren:
sudo networksetup -setv6automatic "iPhone USB"Siehe auch https://support.nordvpn.com/hc/en-us/articles/19924913336081-How-to-disable-IPv6-on-macOS
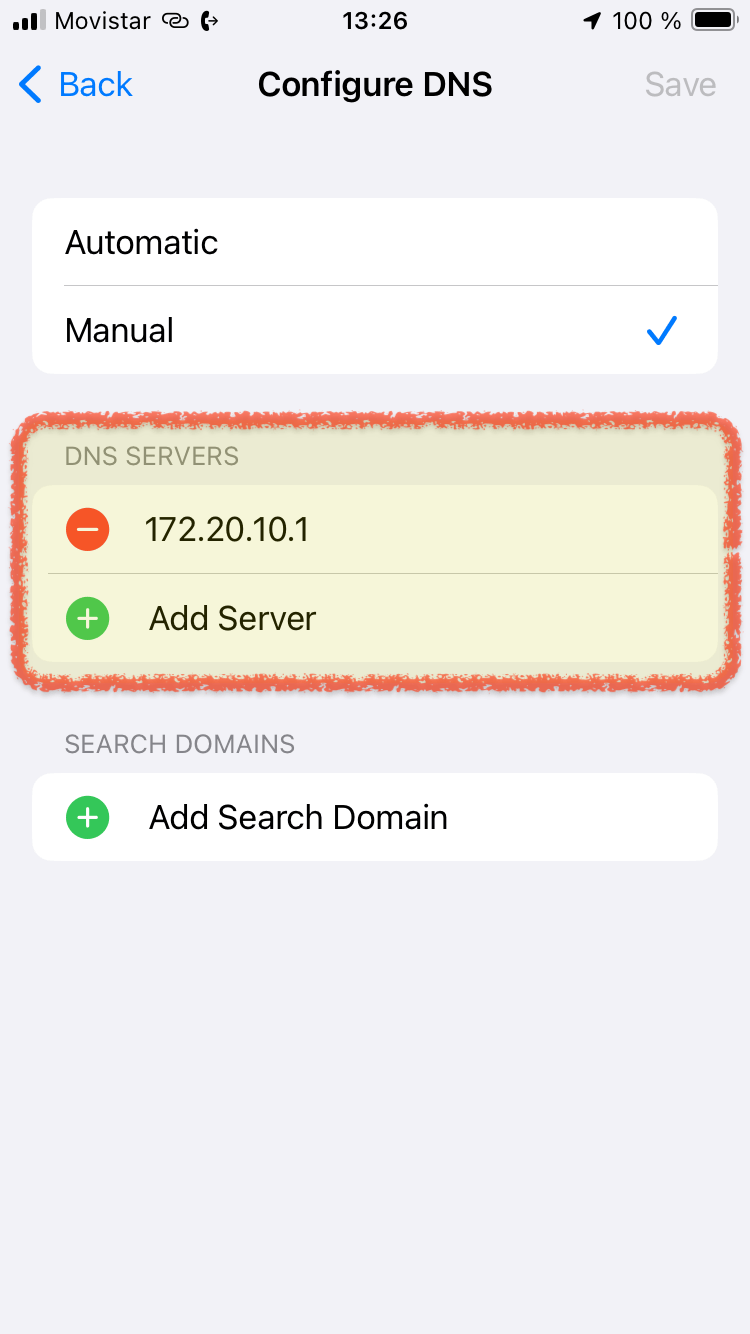
Am iPhone / iPad, das den Personal Hotspot nutzen soll: iPv4 und DNS manuell konfigurieren.
- Als manuelle IP Adresse können 172.20.10.2 bis 172.20.10.14 genutzt werden.
- Am besten von oben beginnen, um Konflikte möglichst zu vermeiden (z.B. wenn Macbooks eine automatische IP Adresse zugewiesen wird).